2022년 테크 업계 번아웃 실태 보고
참고: 직원들의 동기 부여와 사기를 관리하는데 도움을 주는 서비스를 파는 회사에서 만든 보고서입니다.
번아웃의 의의
- 글로벌 경쟁으로 인해 테크 업계 직원들은 오래 근무하고 시간 압박에 시달린다. 정신이나 육체가 회복할 여유가 없이 이런 일들이 매일 매일 반복되다 보면, 아래와 같은 번아웃의 증상들이 나타난다.
- 번아웃은 현재 전세계 수많은 사람이 직장을 그만두고 있는, 일명 ‘2021년 대퇴사 물결’(The Great Resignation of 2021)의 원인 중 하나로 꼽힌다.
- 번아웃 자가진단: https://burnoutindex.yerbo.co
번아웃의 4가지 증상
- 감정 소모나 활력 고갈 (emotional or energetic exhaustion)
- 무능감 (self-inefficacy)
- 냉소 (cynicism)
- 비인격화 (depersonalization)
감정 소모, 활력 고갈
- 하루 일과가 끝나고 미처 회복할 겨를도 없이 다음 날 업무를 시작한다.
- 고갈, 신경쇠약, 피로감으로 인해 업무를 제대로 못하게 된다.
- 우울증, 심혈관 질환, 스트레스와 연관된 각종 질병들이 생긴다.
- 56%의 IT 노동자들은 업무 시간이 끝나도 제대로된 휴식을 취하지 못한다.
무능감
- 자신의 능력을 의심하기 시작한다.
- 맡은 역할을 잘 완수할 능력이 있음에도 자신감이 떨어지고 성취감이 줄어 들어 점차 생산성이 떨어지고 의욕이 꺾인다.
- 정서적으로 흔들리기 시작하여 일을 미루기 시작하고, 결국 가면 증후군(Imposter Syndrome)에 걸릴 수 있다.
- 51%의 사람들은 업무 결과물이 자신의 능력에 못 미치고 있다고 느낀다.
냉소
- 사람을 변덕스럽게 만들고, 원래 친절하게 대했던 사람들에게 차갑게 대한다.
- 자신의 노력이 인정받지 못한다고 느껴 목표를 달성하고 업무를 완수하는 것에 더이상 만족감과 의미를 찾지 못한다.
- 이직을 예측할 수 있는 가장 확실한 지표다.
- 27%의 응답자들은 자신이 하는 일의 가치와 목적을 모른다.
비인격화 (분리, 소외감, 자아 상실) / 심리적 무감각
- 현 상황에 대처하고 업무를 이어가기 위한 방어 기제로써 감정을 억제한다.
- 동료, 고객, 상사에게 차갑게 대하고 거리를 둔다.
- 소속감을 느끼지 못하고, 나아가 전체 조직 분위기를 부정적으로 물들일 수도 있다.
- 22%는 같이 일하는 동료에게 자신이 지나치게 적대적으로 대하는거 같다고 응답했다.
매니저와 회사를 위한 조언
- 번아웃 고위험군의 42.1%는 6개월 안에 직장을 떠날 계획이라 밝혔다.
- 저위험군의 76%는 직장에 계속 남을 것이라 밝혔다.
- 번아웃을 없애는 일회성 기법은 없다. 회식이나 유급 휴가로 해결할 수 없다.
- 동기 부여에 도움이 되는 멘토링, 좋은 사우 관계, 성장/승진의 기회 등은 일시적으로나마 번아웃과 싸워 이길 수 있는 면역력을 키워준다.
Tags: burnout in tech
[유머] 왜 소프트웨어 개발은 예상보다 2~3배 더 오래 걸리는가?
Quora에 올라온 답변을 번역 및 재구성한 글입니다.
해운대에 사는 친구를 만나러 갈 겸 속초에서 부산까지 도보 여행을 가기로 했다. 지도를 켜서 동해안을 따라 길을 그려봤다.
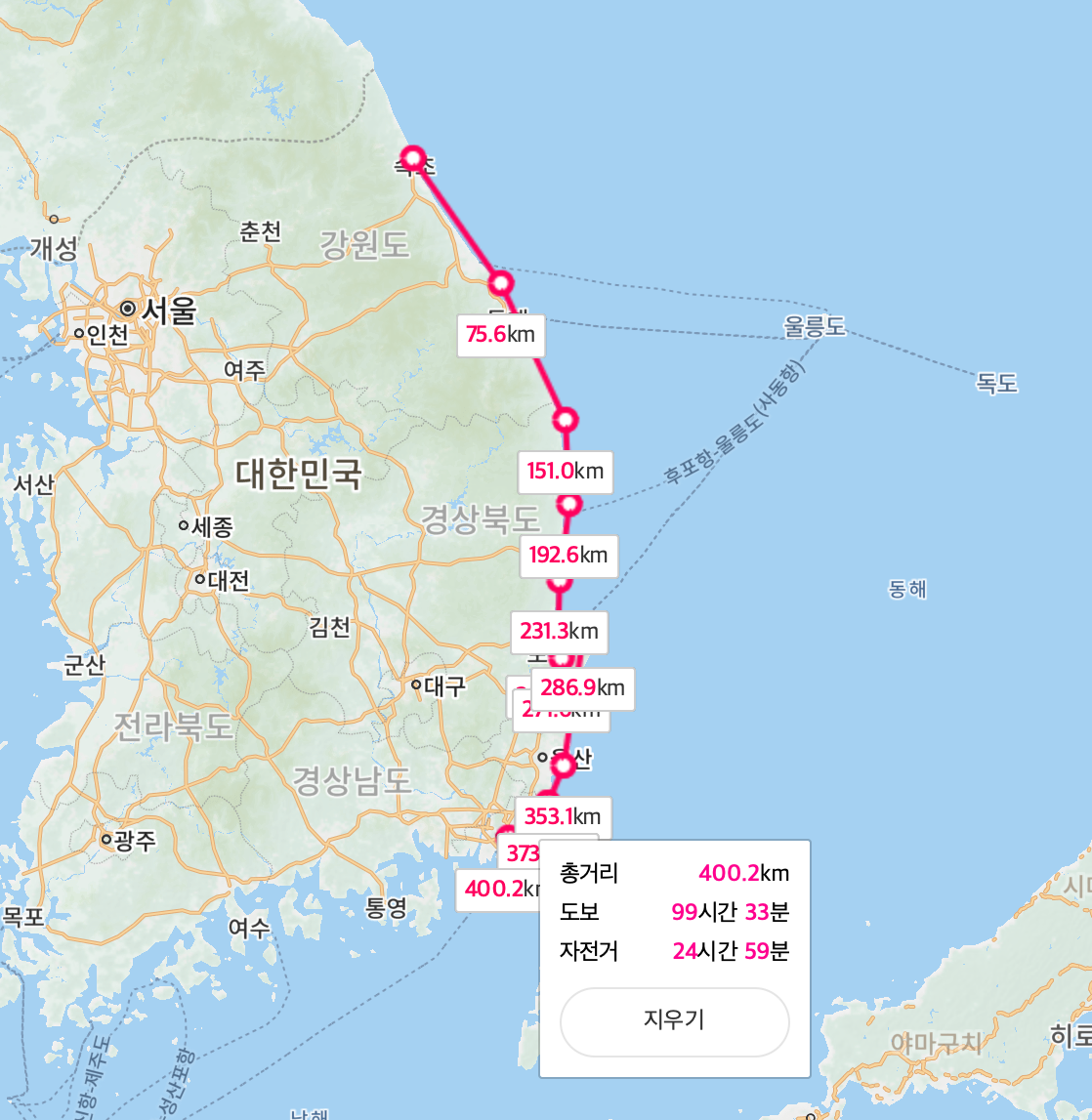
대략 400km 정도다. 한시간에 4km를 걷는다고 했을때 총 100시간이 걸리고, 하루에 10시간 정도 걸을 수 있으니 총 10일이 걸릴 것으로 예상한다. 지도에도 이렇게 나오니 더욱 자신있게 친구한테 전화해서 다음주 일요일 밤에 도착할 예정이니 해운대 최고의 횟집을 예약해놓으라고 한다. 너무 기대된다!
흥미진진한 여행을 기대하며 다음날 일찍 일어났다. 동행하는 친구와 함께 가방을 메고 나섰다. 첫 날의 종착지를 정하기 위해 지도를 꺼냈다. 앗..
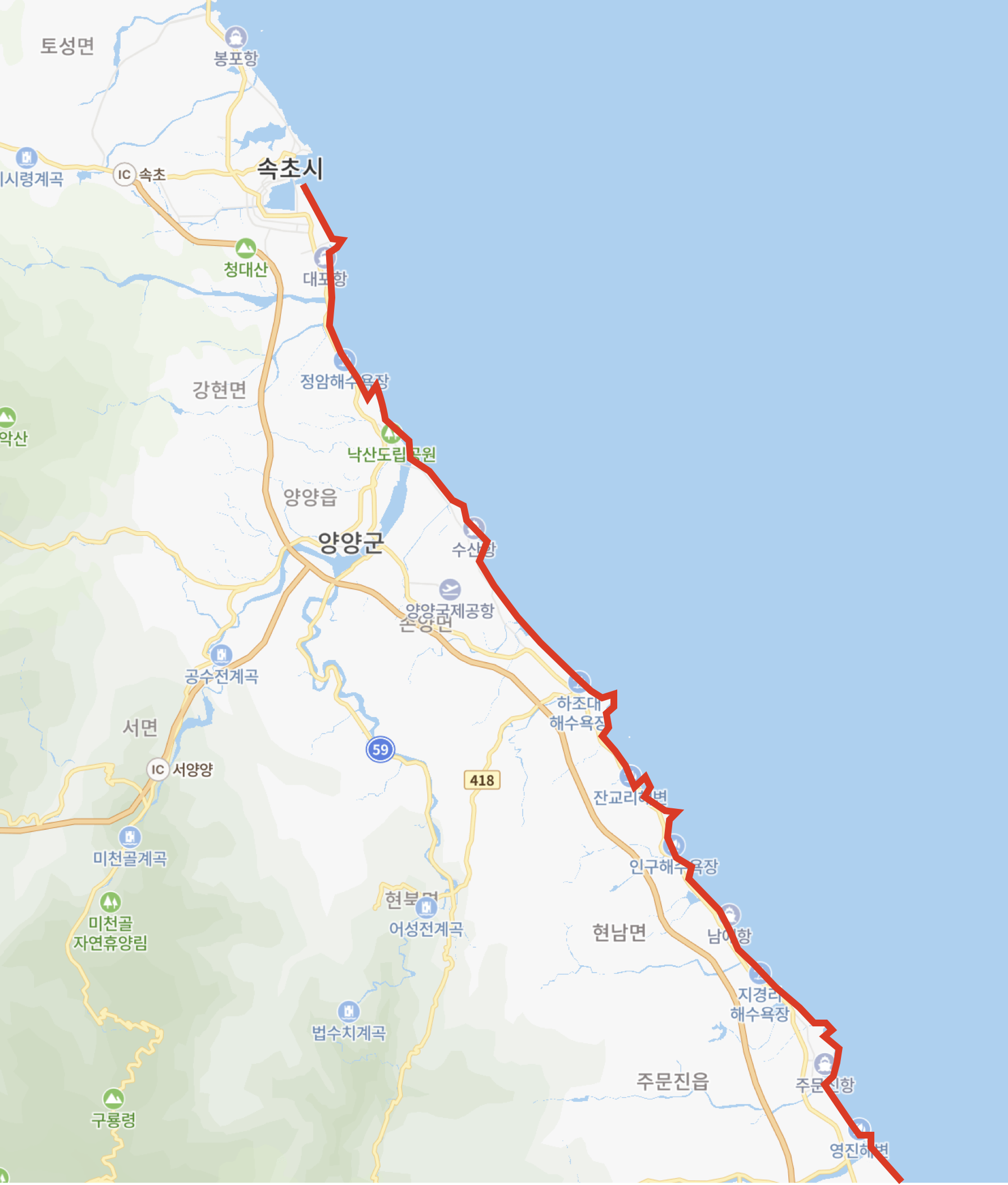
동해안이라고 방심했는데 자세히보니 해안선이 생각보다 엄청 구불구불하다. 하루에 40km를 가야하는데 이대로라면 겨우 양양까지 밖에 못갈거 같다. 400km가 아니라 500km짜리 여행이 될 것 같다. 친구한테 다시 전화해서 저녁 약속을 화요일로 미룬다. 일정은 현실적으로 잡아야하니까. 친구는 잠깐 실망하지만 오랜만에 만날 생각에 들떠있다. 속초에서 부산까지 12일이면 여전히 나쁘지 않다.
일정의 부담을 덜고나서 드디어 여행을 시작한다. 두시간이 지나 이제 겨우 속초 시내를 벗어났는데 이게 무슨 일이야? 눈 앞에 펼쳐진 길을 보고 놀란다.

한시간에 4km를 꾸준히 걷는 것이 힘들다는걸 깨닫는다. 모래 사장, 바다, 계단, 곶과 만이 즐비하다. 한시간에 2km 밖에 걷지 못하고 있다. 지금 속도대로 라면 하루에 20시간 걷던가, 친구와의 약속을 일주일 더 미뤄야할 판이다. 그래, 적당히 타협을 하자. 하루에 12시간 걷는 대신 친구와 약속은 주말로 미루기로 한다. 친구는 조금 짜증을 냈지만, 어쩔수 없지. 그때 보기로 한다.
힘들게 12시간을 걸은 후 주문진의 한 해수욕장에 야영하기로 한다. 젠장, 바람이 너무 많이 불어서 텐트를 치는게 너무 어렵다. 결국 자정이 다 돼서야 겨우 잠에 든다. 이정도 쯤이야. 심기일전하여 내일 속도를 높여보기로 한다.
늦잠을 자버리고 온몸이 욱씬 거리는 상태로 오전 10시에 일어난다. 🤬 18! 오늘 12시간을 걷는건 무리다. 오늘 10시간 걷고 내일 14시간을 걷자. 짐을 싸서 출발한다.
묵묵히 두어 시간을 걸었을까, 친구가 절뚝거리기 시작했다. 제길, 물집이 잡혔다. 지금 물집을 해결하고 가야한다. 우리는 문제가 더 커지기 전에 싹을 제거하는 팀이니까. 45분 동안 내륙에 있는 시내까지 달려 약국에서 연고와 밴드를 사서 돌아온 후 친구를 응급처치 해준다. 나는 벌써 기진맥진하고, 해는 지고 있다. 오늘은 여기서 마무리하기로 한다. 오늘은 6km만 걸은 채로 잠을 청한다. 하지만 오늘 기력을 회복했으니 앞으로 괜찮을거다. 오늘 못한건 내일 메꾸자.
다음날 일어나서 발바닥에 붕대를 감고 다시 길에 오른다. 길목을 돌아서니 장관이 펼쳐진다. 아니 이게 뭐지?

망할, 지도에는 이런게 안나왔다. 하는 수 없이 내륙으로 3km 들어가 철조망이 쳐진 산 속 군 부대를 빙 둘러가다가 길을 두번 잃고 다시 해안가로 돌아오니 정오가 다 됐다. 고작 1km 전진했는데 하루의 절반이 지나 갔다. 약속 날짜를 또 미룰순 없다. 결국 계획대로 가기 위해 자정까지 걷는다.
춥고 안개 낀 날씨에 밤잠을 설친 친구는 아침부터 깨질듯한 두통과 고열에 시달린다. 여행할 채비를 할 수 있느냐 친구에게 묻는다. ‘제정신이냐 미친놈아. 3일 동안 쉬지도 못하고 추위를 참아가며 걸었는데!’ 오늘은 쉬면서 회복하는 수 밖에 없다. 하루 쉬었으니 내일부터는 하루에 14시간씩 걸을 체력이 있겠지. 몇 일만 하면 되니까 힘내자! 할 수 있다!
다음날 축 처진 채로 일어나 지도를 본다.
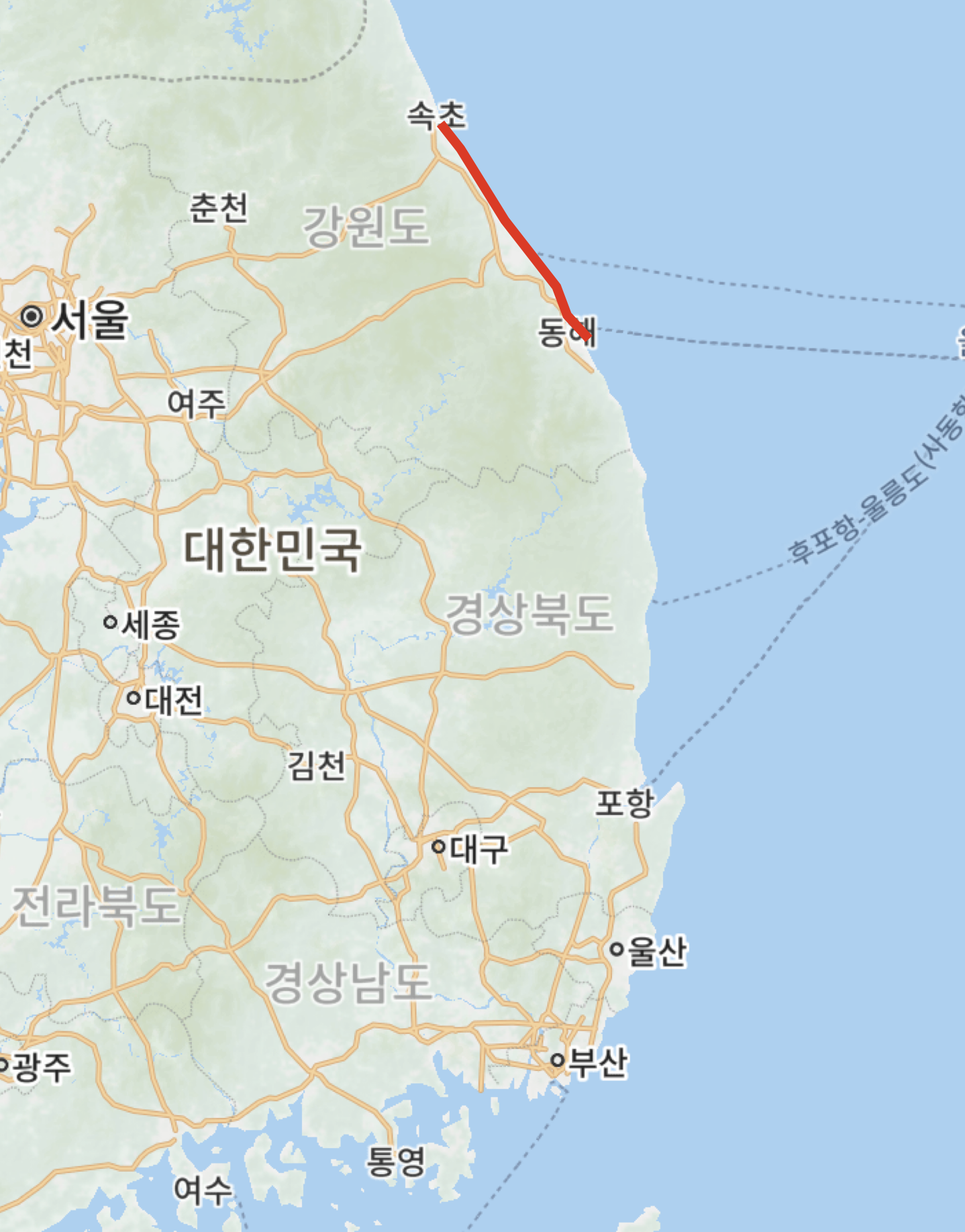
이럴수가, 열흘짜리 여행에 5일차 아침인데 아직 강원도도 못 벗어났다! 터무니 없는 상황이다. 다시 한번 정확히 일정을 산정해보자. 친구한테 욕 좀 더 먹겠지만 진짜 마지막으로 현실적인 목표를 세워보자.
친구가 말하길, “나흘 동안 40km를 왔는데 해운대까지 최소 600km인거 같으니 최소 60일이고, 좀 더 보수적으로 잡으면 70일 정도일거 같다.” 나는 말했다. “그럴리가 없다. 나도 직접 해본적은 없지만 속초에서 해운대까지 70일이 걸리는건 진짜 말이 안된다. 기다리고 있는 친구한테 추석 쯤 도착한다고 하면 비웃겠지!””
내가 이어 말했다. “하루에 16시간 걷기로 다짐하면 해낼수 있다! 힘들겠지만 이제부터 크런치 모드다. 참고 받아들여!” 친구가 맞받아친다. “친구한테 일요일까지 도착하겠다고 한건 너야 인마! 너가 실수한거 때문에 내가 죽게 생겼어!”
우리 사이에 긴장감 가득찬 침묵이 지속된다. 차마 해운대 사는 친구에게 전화를 하지 못했다. 이성을 찾은 친구가 좀 더 합리적인 계획에 동의를 하고 나면 내일쯤 전화를 해봐야겠다.
다음날 아침, 우리는 비바람이 그칠 때까지 텐트에 머문다. 짐을 챙겨 오전 10시에 길을 나선다. 근육통과 새로 생긴 물집을 참아가며. 누구도 어제 밤의 말다툼은 언급하지 않는다. 그러다가 멍청이 친구가 물병을 놓고 오는 바람에 다시 30분을 왔던 길로 돌아가게 되자 정신줄을 놓고 윽박지른다.
휴지가 다 떨어져서 다음 들르는 동네에서는 잊지 않고 구매해야한다고 할일 목록에 적어 논다. 골짜기를 넘어가니 장마로 불어난 강이 육교를 집어삼켰다. 순간 참을 수 없는 설사가 밀려오는걸 느낀다…
Tags: software development estimation
모바일 개발자를 위한 30-60-90일 성공 계획서
30-60-90 Days Success Plan
“30-60-90 Days Success Plan”은 개발자가 Momenti 모바일 팀에 적응하고 기대하는 역량을 발휘하고 있는지 판단하는 기준이 되는 문서다. 신규 입사자가 새로운 환경에 적응하고 새 조직에서 성공하기 위해서는 입사 후 첫 90일이 정말 중요하다고 한다. 새로 합류한 개발자는 이 문서를 토대로 입사 후 자신의 목표를 설정할 수 있고 올바른 방향으로 가고 있는지 스스로 판단해 볼 수 있다. 그리고 기존 팀원은 새 팀원이 아래 목표를 달성할 수 있게 적극 도와야 한다. 지식 전달을 해주고 역량을 키울 수 있는 역할과 업무를 부여해주고 피드백을 줘야한다.
또한 Momenti 모바일 팀이 신규 입사자에게 기대하는 역량과 성장 속도를 가늠하는 척도가 된다. 면접볼 때는 채용 후보자가 팀의 기대를 충족시키거나 초과할 수 있는 사람인지 봐야한다.
For Junior
30일차: 개발 프로세스/컨벤션/코드 파악, RIBs 학습, 도메인 습득
- 프로젝트를 빌드하고, 빌드 에러를 해결할 수 있다.
- 간단한 기능이나 버그를 수정할 수 있다.
- PR을 올리고 리뷰를 받고 머지할 수 있다.
- 주요 도메인 모델(███, ███, ███, ██)의 구조과 동작 방식을 이해한다.
- 하나의 화면에 대한 UI와 비즈니스 로직을 RIBs로 구현할 수 있다.
- 자주 사용하는 모듈이나 객체의 존재 유무와 사용법을 이해한다.
- 데모 모먼트 6개 중 최소 1개를 만들수 있다.
60일차: 테스트코드 작성, 프로젝트/도메인 이해, 개발 프로세스 적응
- 하나의 Riblet 또는 간단한 구현 객체에 대한 UI, 비즈니스 로직, 유닛 테스트를 작성할 수 있다.
- 간단한 구현 객체란 협력 객체가 0~2개 정도되는 Imp 객체를 의미함
- 도메인 모델의 세부 사항을 이해하고 ███ 엔진과 앱 간의 상호 작용(각각의 역할, 데이터의 흐름)을 이해한다.
- 큰 작업을 여러 개의 의미있는 PR로 쪼개서 개발할 수 있다.
90일차: 프로젝트의 일부분을 성공적으로 완수, 동료의 신뢰 얻기, 장기적 성장 계획 수립
- 백엔드, UX 등 다른 팀 담당자와 직접 소통하고 일정에 맞춰 맡은 부분을 완료할 수 있다.
- 난이도 ‘중’ 이하의 업무를 동료의 도움을 받아 완수할 수 있다.
- 작업을 팀의 기준에 부합하는 사이즈의 PR로 쪼개서 진행할 수 있다.
- 코드 리뷰를 통해 프로젝트의 코드 품질, 기능 개발에 긍정적인 기여를 할 수 있다.
- 업무에 필요한 추가적인 정보나 성장에 필요한 자원을 시니어나 매니저에게 스스로 요청할 수 있다.
- 다른 주니어 입사자를 초기에 온보딩 시켜 줄 수 있다.
For Senior
Senior의 Success Plan은 Junior의 모든 항목을 포함하며 Junior보다 더 빨리 달성하기를 기대한다. Senior는 60일차 정도에 Junior의 90일차 목표를 달성하기를 기대한다. 아래 항목은 추가적으로 Senior에게 기대하는 부분만 포함한다.
30일차: 코드, 프로세스, 컨벤션 파악, 도메인 습득, 기능 개발에 기여
- 간단한 기능을 담당하거나 복잡한 기능의 일부분 개발에 기여할 수 있다.
60일차: 프로젝트 구조 대체로 파악, 본격적인 기능 개발
- 중규모 이하의 모듈 하나를 담당해서 개발하고 자동화 테스트를 구축할 수 있다.
- 때때로 팀의 대표로 다른 팀과 소통하고 스펙 논의에 참여하여 정보를 정리하고 전달할 수 있다.
90일차: 개발 리딩, 조직 및 도메인 수준에서 발전에 기여. 처음 겪는 문제 해결
- 엔진, 백엔드, UI/UX, 모바일 등 세 개 이상의 팀이 협업해야하는 복잡한 기능 개발을 리딩할 수 있다.
- 아키텍처를 개선하는 방향으로 모듈을 설계, 개발, 리팩토링을 할 수 있다.
- 스펙 논의를 주도할 수 있고 다른 사람들이 놓친 세부 사항이나 예외 사항를 발견하여 메울 수 있다.
- 코드 작성자가 놓쳤거나 미흡한 부분을 코드 리뷰에서 발견하여 문제를 조기에 방지할 수 있다.
- 코드나 프로세스의 개선점을 찾아 동료들의 생산성을 향상시킬 수 있다.
Tags: success plan, momenti mobile
터치 시뮬레이션을 활용한 단위 테스팅
작년부터 도입하여 사용중인 터치 시뮬레이션을 이용한 단위 테스트 소개.
의의
- 유닛 테스팅 번들이라서 UI 테스트 마냥 앱 전체를 빌드, 설치하지 않고 원하는 모듈만 빌드하여 테스트할 수 있어서 빠르다. 테스트 하려는 화면이나 모듈 갯수를 유연하게 정할 수 있다.
- 뷰, 비즈니스 로직, 라우팅, 서비스 계층까지 이어지는 유저 플로우 전체를 실 객체로 테스트할 수 있다. 테스트에서 주입한 mock 네트워크나 데이터 저장 계층을 가지고 최종 행위나 상태를 검증하게 됨. 테스트의 신뢰성이 높고, 내부 구현이 바뀌어도 테스트가 바뀔 경우가 많이 없음.
위험
- Private API를 쓰고 있어서 혹시나 미래에 막힐까 하는 걱정.
계기
각 테스트의 ‘단위’를 얼만큼으로 잡을 것인가는 테스트의 속도 vs 효과성 트레이드오프를 파악하여 정해야 한다. 단위를 매우 작게 잡으면 속도는 빠르지만 실세계와 테스트 환경의 괴리가 크므로 효과성이 낮다. 단위를 크게 잡을수록 속도는 느리지만 효과성이 높다. 테스트 대상을 최대로 크게 잡은게 UI Test고, 가장 작게 잡은건 sut가 객체 하나짜리인 단위 테스트라고 볼 수 있다.
모바일 앱에서 테스트가 필요한 여러 기능 중 중요도가 높은건 사용자의 인터랙션과 복잡하게 얽힌 플로우다. 많은 버그가 사용자의 인풋을 올바르게 처리하지 못해서 발생한다. 그런데 유닛 테스트에서 사용자의 인풋을 발생시키는 방법이 마땅치 않다.
(1) control에 직접 sendActions를 호출한다.
테스트 때문에 private 접근자를 빼야하므로 싫음.
(2) 뷰를 모킹하여 사용자 인풋을 흉내낸다.
현실과 괴리감이 커지고, 경험상 구현이 바뀌면 테스트 코드도 빈번히 수정됨.
특히 2번 때문에 해결법을 찾고자 했던건데, 예전에 UI는 그대로인 상태에서 기능이 추가/수정 됐는데 테스트 코드도 많은 부분 다시 작성했던 경험을 하고나서 충격을 받았고 그때 뭔가 잘못됐다는 느낌이 왔다.
두 문제를 해결해주는게 Hammer라는 라이브러리다. RIBs로 치면 뷰, 인터랙터, 라우터를 전부 실 객체로 테스트할 수 있다는 뜻이다. 더 나아가 인터랙터가 호출하는 서비스 계층도 실 객체를 쓸 수도 있다. 모멘티 프로젝트는 서비스 계층이 의존하고 있는 플랫폼 계층(네트워킹, 데이터 저장, 엔진 등)이 한 단계 더 있어서 실 서비스 객체까지 테스트할 수 있다. Hammer를 사용하면 테스트의 인풋은 실세계와 매우 유사한 유저 터치이며 모킹된 플랫폼 계층에서 최종 행위/상태 검증을 할 수 있다. 신뢰도가 높으면서 유연하고 빠른 테스트를 만들 수 있다.
Tags: unit testing, touch simulation